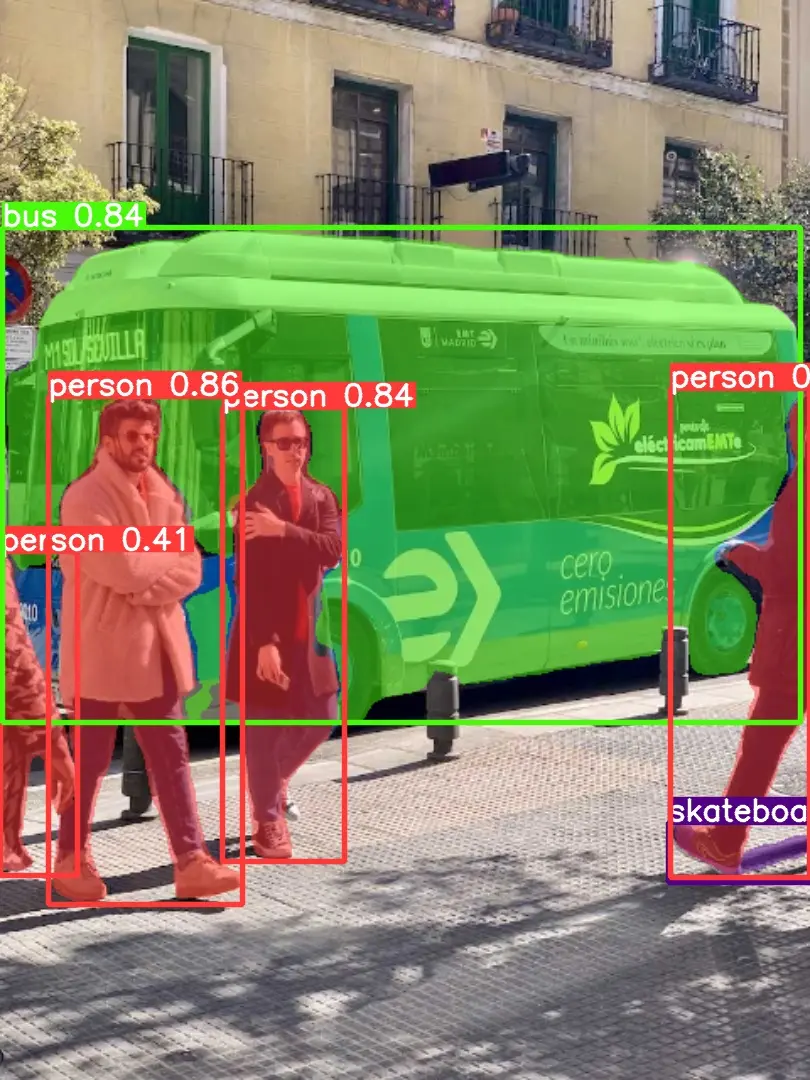
该章节教大家如何突破tensorrt加速默认推理尺寸(640*640)的限制,全网该类教程几乎没有,看到就是赚到!!!
问题描述:
可以想象这样一个场景:我们有一个1280*720的私人数据集,在进行正常的训练、验证、tensorrt转换、用engine文件推理,engine文件推理时,发现终端栏显示(160 * 640)的一个尺寸,这与我们的数据集尺寸不匹配。
我当时注意到这个问题,就在想如何做到推理与数据集尺寸匹配呢?

首先我查看了YOLOV8的官方文档,在模型训练和推理时可以设置imgsz参数,我当即在运行脚本设置了imgsz=(720,1280)
注:参数格式imgsz=(h,w),先输入h,再输入w。
输入之后:
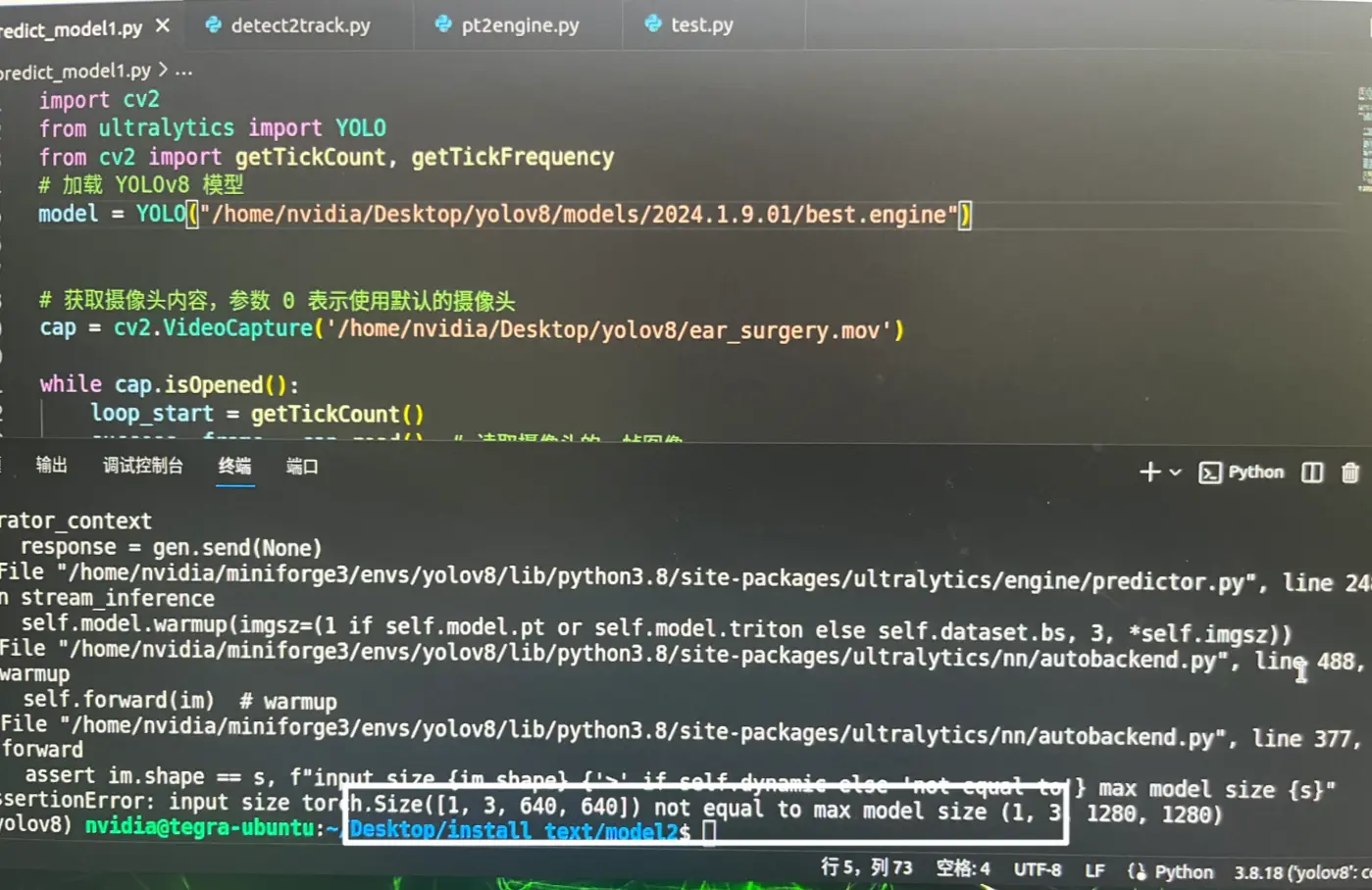
报错:input size torch.Size([1,3,640,640]) not equal to max model size (1,3,1280,1280)
会不会是训练和转换时没设置参数导致该问题?
于是我添加 imgsz=[1280,720]参数,并重新训练
注:训练时的imgsz参数格式是imgsz=[w,h]
训练脚本:
1
2
3
4
5
6
7
8
9
10
| from ultralytics import YOLO
# 加载模型
model = YOLO('yolov8n-seg.yaml').load('yolov8n-seg.pt') # 从YAML构建并转移权重
if __name__ == '__main__':
# 训练模型
results = model.train(data='seg.yaml', epochs=100, imgsz=[1280,720]) #
metrics = model.val()
|
训练结束得到best.pt文件,我们进行tensorrt加速,pt转化engine文件:
pt转化engine脚本:
1
2
3
4
5
6
7
| from ultralytics import YOLO
# Load a model
model = YOLO('best.pt') # load a custom trained
# Export the model
model.export(format='engine',half=True,simplify=True,imgsz=(736,1280))
|
注:转换时的imgsz参数格式是imgsz=[w,h]
最终还是报错:input size torch.Size([1,3,640,640]) not equal to max model size (1,3,1280,1280)`
我搜集了全网都没有找到相关答案(甚至看了YOLOv8作者的答案都无法解决问题)
解决方法:
耗时半个月,我终于找到了解决方法,以上步骤是完全正确的,大家可以放心学,我们只需要修改yolo的代码参数就能正常推理engine文件了。
首先,找到ultralytics/nn/autobackend.py文件,打开,ctrl+f 搜索warmup

把(1,3,640,640)改成(1,3,720,1280)
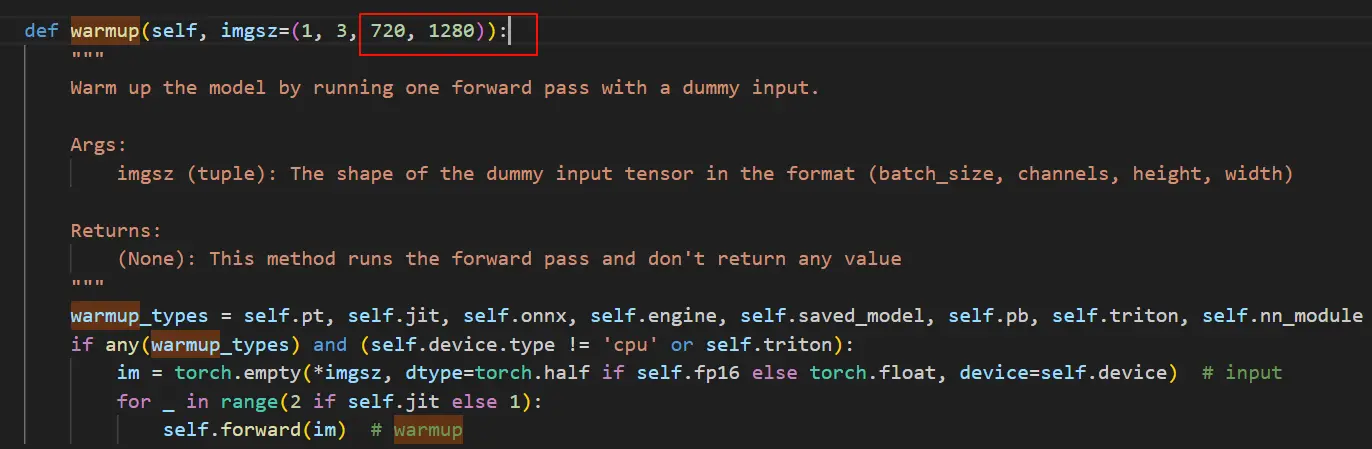
ctrl+s保存,接着我们在运行脚本添加imgsz=(720,1280)参数后就可以推理啦
最后给大家分享我的运行脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| import cv2
from ultralytics import YOLO
from cv2 import getTickCount, getTickFrequency
# 加载 YOLOv8 模型
model = YOLO("best.engine",task='segment')
# 获取摄像头内容,参数 0 表示使用默认的摄像头
cap = cv2.VideoCapture(0)
while cap.isOpened():
loop_start = getTickCount()
success,frame = cap.read() # 读取摄像头的一帧图像
if success :
results = model.predict(frame,imgsz=(720,1280)) # 对当前帧进行目标检测并显示结果
annotated_frame = results[0].plot()
# 中间放自己的显示程序
loop_time = getTickCount() - loop_start
total_time = loop_time / (getTickFrequency())
FPS = int(1 / total_time)
# 在图像左上角添加FPS文本
fps_text = f"FPS: {FPS:.2f}"
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1
font_thickness = 2
text_color = (0, 255, 0) # 绿色
text_position = (10, 30) # 左上角位置
cv2.putText(annotated_frame, fps_text, text_position, font, font_scale, text_color, font_thickness)
cv2.namedWindow("img",cv2.WINDOW_NORMAL)
cv2.imshow('img', annotated_frame)
# 通过按下 'q' 键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 释放摄像头资源
cv2.destroyAllWindows() # 关闭OpenCV窗口
|
希望我的文章能对你有所帮助,有问题联系邮箱:[email protected]